21.0 Akka与并发编程模型

Akka是一种并发编程模型的框架,其官网为http://akka.io。提供Java版本和Scala版本的API。
从学习或者使用的角度来说,我们首先要说明的是,Akka的并发编程模型(流水线模式)与Java中的并发编程模型(并行者模式)有什么区别。
1、Java中的并行工作者模式
并行工作者模型。传入的作业会被分配到不同的工作者上。下图展示了并行工作者模型:
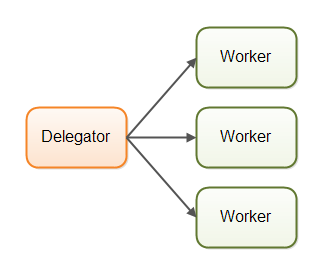
在并行工作者模型中,委派者(Delegator)将传入的作业分配给不同的工作者。每个工作者完成整个任务。工作者们并行运作在不同的线程上,甚至可能在不同的CPU上。
如果在某个汽车厂里实现了并行工作者模型,每台车都会由一个工人来生产。工人们将拿到汽车的生产规格,并且从头到尾负责所有工作。
在Java应用系统中,并行工作者模型是最常见的并发模型(即使正在转变)。java.util.concurrent包中的许多并发实用工具都是设计用于这个模型的。你也可以在Java企业级(J2EE)应用服务器的设计中看到这个模型的踪迹。
并行工作者当然有着自己的有点,在这里我们主要讨论的是其缺点:
在实际应用中,并行工作者模型可能比前面所描述的情况要复杂得多。共享的工作者经常需要访问一些共享数据,无论是内存中的或者共享的数据库中的。下图展示了并行工作者模型是如何变得复杂的:
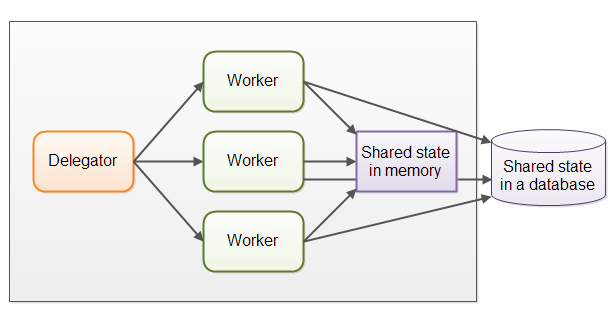
有些共享状态是在像作业队列这样的通信机制下。但也有一些共享状态是业务数据,数据缓存,数据库连接池等。
一旦共享状态潜入到并行工作者模型中,将会使情况变得复杂起来。线程需要以某种方式存取共享数据,以确保某个线程的修改能够对其他线程可见(数据修改需要同步到主存中,不仅仅将数据保存在执行这个线程的CPU的缓存中)。线程需要避免竟态,死锁以及很多其他共享状态的并发性问题。
此外,在等待访问共享数据结构时,线程之间的互相等待将会丢失部分并行性。许多并发数据结构是阻塞的,意味着在任何一个时间只有一个或者很少的线程 能够访问。这样会导致在这些共享数据结构上出现竞争状态。在执行需要访问共享数据结构部分的代码时,高竞争基本上会导致执行时出现一定程度的串行化。
现在的非阻塞并发算法也许可以降低竞争并提升性能,但是非阻塞算法的实现比较困难。
2、Akka中的流水线模式
第二种并发模型我们称之为流水线并发模型。我之所以选用这个名字,只是为了配合“并行工作者”的隐喻。其他开发者可能会根据平台或社区选择其他称呼(比如说反应器系统,或事件驱动系统)。下图表示一个流水线并发模型:

类似于工厂中生产线上的工人们那样组织工作者。每个工作者只负责作业中的部分工作。当完成了自己的这部分工作时工作者会将作业转发给下一个工作者。每个工作者在自己的线程中运行,并且不会和其他工作者共享状态。有时也被称为无共享并行模型。
通常使用非阻塞的IO来设计使用流水线并发模型的系统。非阻塞IO意味着,一旦某个工作者开始一个IO操作的时候(比如读取文件或从网络连接中读取 数据),这个工作者不会一直等待IO操作的结束。IO操作速度很慢,所以等待IO操作结束很浪费CPU时间。此时CPU可以做一些其他事情。当IO操作完 成的时候,IO操作的结果(比如读出的数据或者数据写完的状态)被传递给下一个工作者。
有了非阻塞IO,就可以使用IO操作确定工作者之间的边界。工作者会尽可能多运行直到遇到并启动一个IO操作。然后交出作业的控制权。当IO操作完成的时候,在流水线上的下一个工作者继续进行操作,直到它也遇到并启动一个IO操作。

在实际应用中,作业有可能不会沿着单一流水线进行。由于大多数系统可以执行多个作业,作业从一个工作者流向另一个工作者取决于作业需要做的工作。在实际中可能会有多个不同的虚拟流水线同时运行。这是现实当中作业在流水线系统中可能的移动情况:

作业甚至也有可能被转发到超过一个工作者上并发处理。比如说,作业有可能被同时转发到作业执行器和作业日志器。下图说明了三条流水线是如何通过将作业转发给同一个工作者(中间流水线的最后一个工作者)来完成作业:

流水线有时候比这个情况更加复杂。
采用流水线并发模型的系统有时候也称为反应器系统或事件驱动系统。系统内的工作者对系统内出现的事件做出反应,这些事件也有可能来自于外部世界或者 发自其他工作者。事件可以是传入的HTTP请求,也可以是某个文件成功加载到内存中等。在写这篇文章的时候,已经有很多有趣的反应器/事件驱动平台可以使 用了,并且不久的将来会有更多。比较流行的似乎是这几个:
* Vert.x
* AKKa
* Node.JS(JavaScript)
对于使用Scala的开发者来说,目前我们应当感兴趣的是Akka。在Akka中,每一个工作者称之为一个Actor。
在Actor模型中每个工作者被称为actor。Actor之间可以直接异步地发送和处理消息。Actor可以被用来实现一个或多个像前文描述的那样的作业处理流水线。下图给出了Actor模型:

相比并行工作者模型,流水线并发模型具有几个优点,在接下来我会介绍几个最大的优点。
1)无需共享的状态
工作者之间无需共享状态,意味着实现的时候无需考虑所有因并发访问共享对象而产生的并发性问题。这使得在实现工作者的时候变得非常容易。在实现工作者的时候就好像是单个线程在处理工作-基本上是一个单线程的实现。
2)有状态的工作者
当工作者知道了没有其他线程可以修改它们的数据,工作者可以变成有状态的。对于有状态,我是指,它们可以在内存中保存它们需要操作的数据,只需在最后将更改写回到外部存储系统。因此,有状态的工作者通常比无状态的工作者具有更高的性能。
